In this blog, I am going to play around with spark with databricks running on AWS.
Resources and Credits
AWS Setup
-
Setup a free trial databricks account.

-
Created a new S3 bucket
spark-learningin the cheapest region Ohio.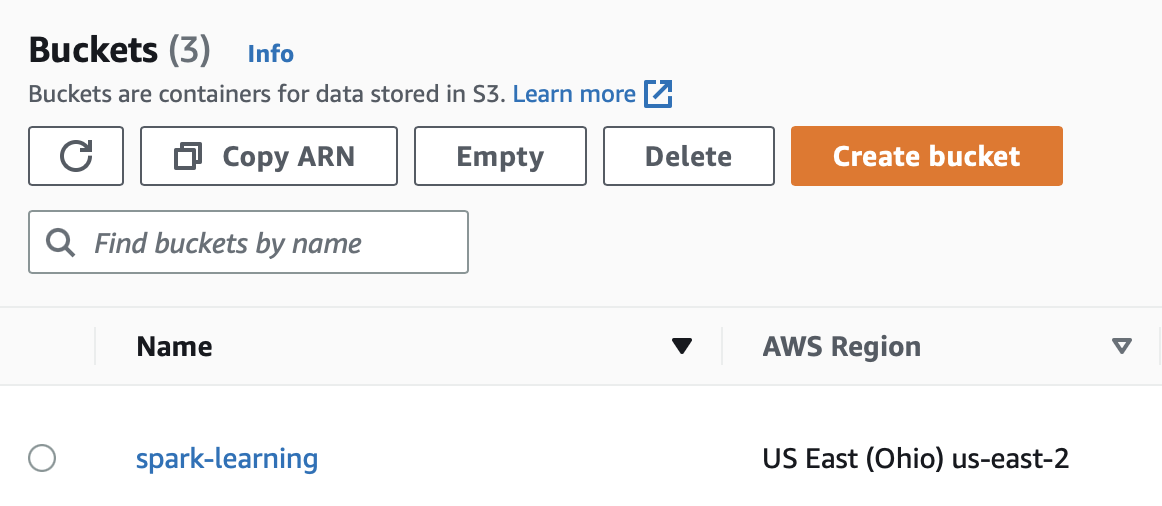
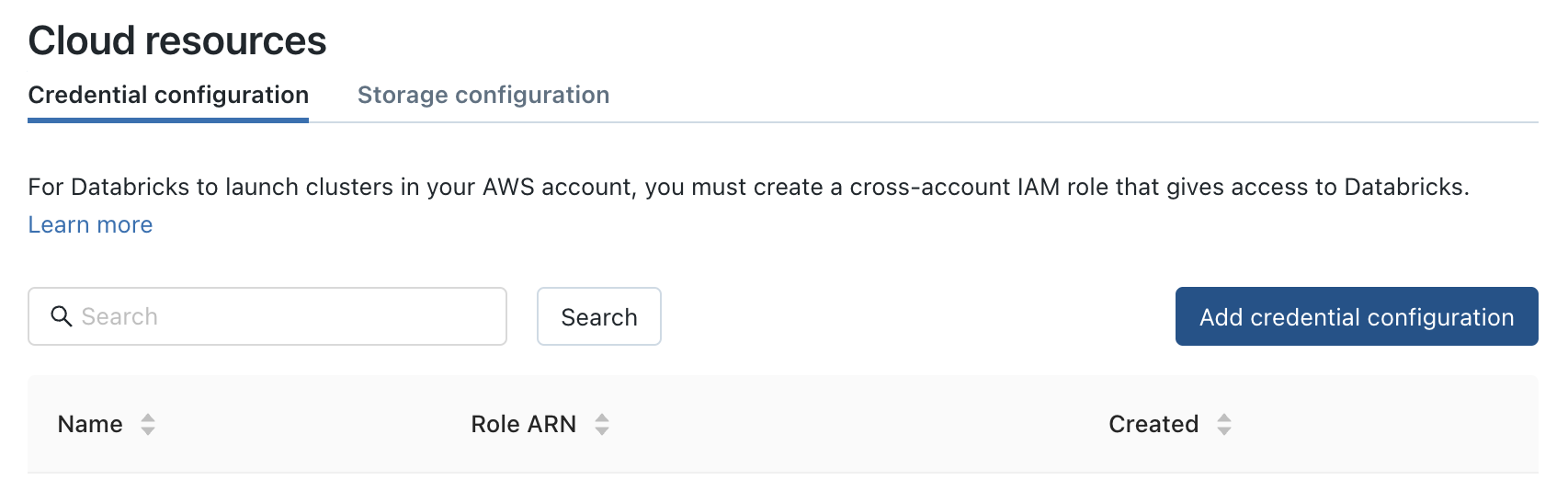
- Credentials configuration: Used this documentation to
- To create a new IAM role with an external AWS account ie., databricks’ account (ID: 414351767826).
-
We also copy our private external account ID from
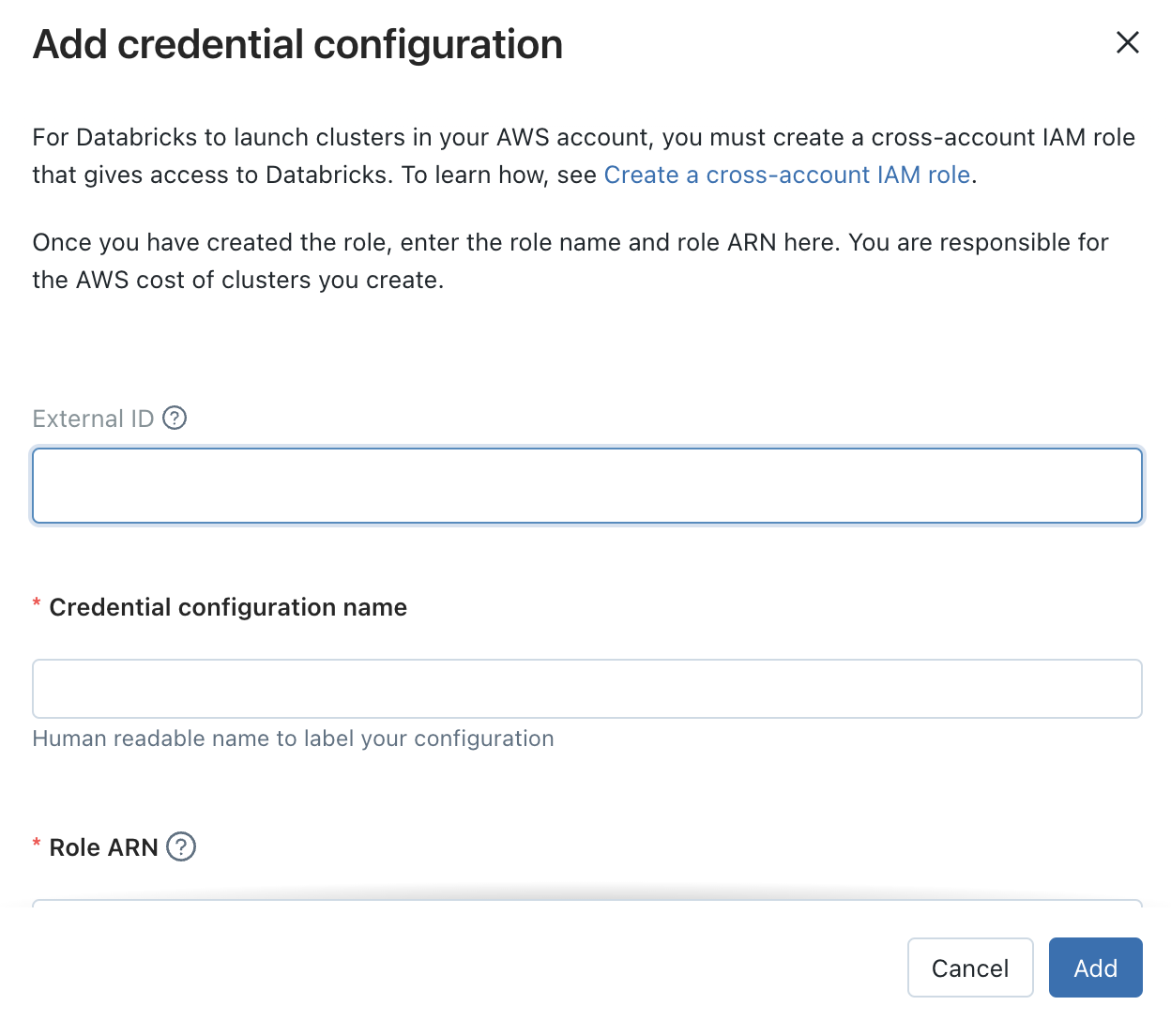
- Attach an inline policy. We copy the JSON for the default policy which sets up spark in databricks’ VPC instead of our private VPC.
- Copy the ARN of the created policy back to databricks credential management.
- Storage credentials:
-
In the databricks storage credentials, added our bucket name and copied the generated policy.
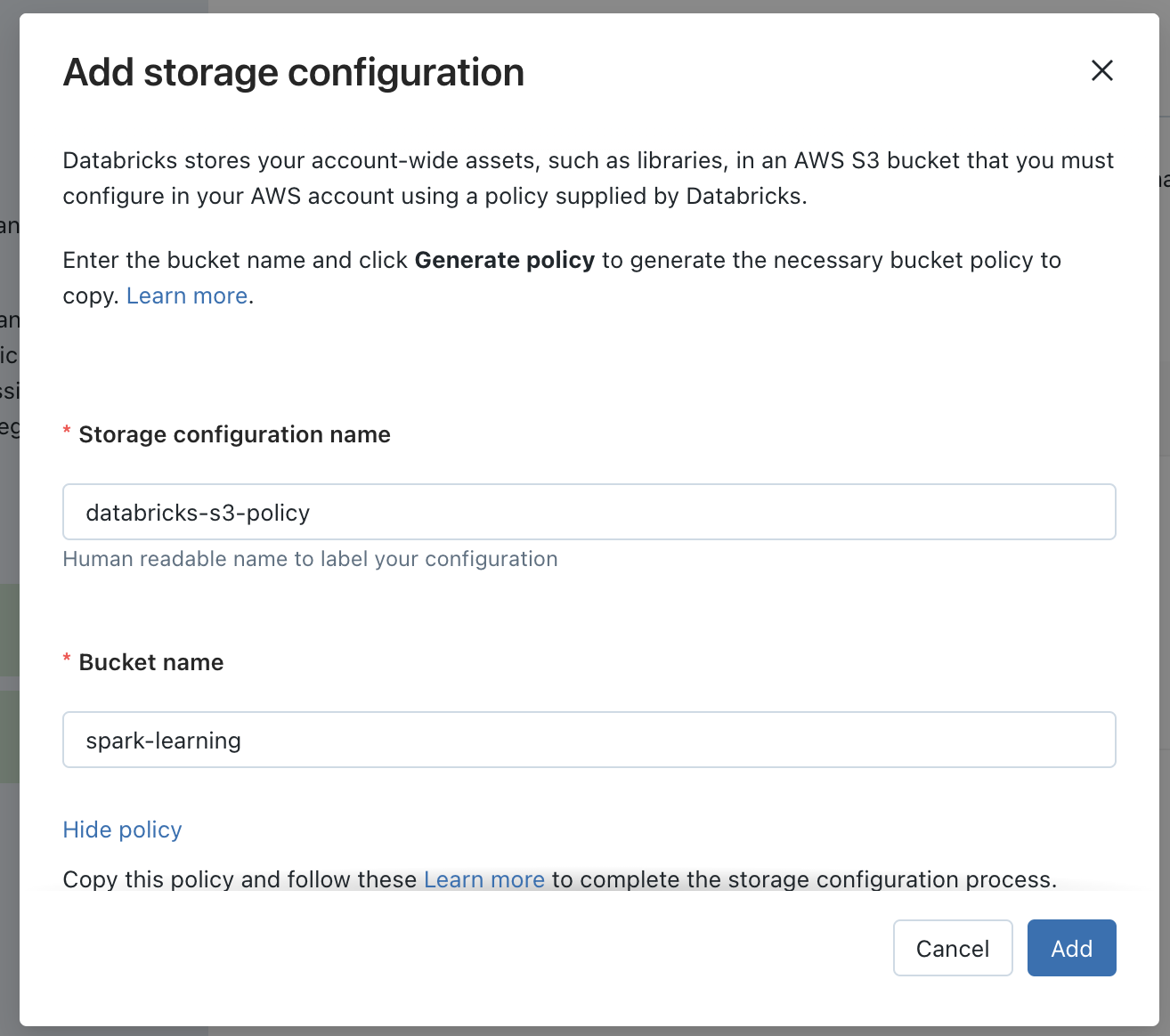
-
In AWS,
S3->buckets->spark-learning->Permissions->Edit bucket policycopied over the JSON policy generated in databricks in the previous step.
-
- We are done with the AWS setup 😄
Databricks Setup
- We create a new workspace with custom creation and apply the credentials we just generated.
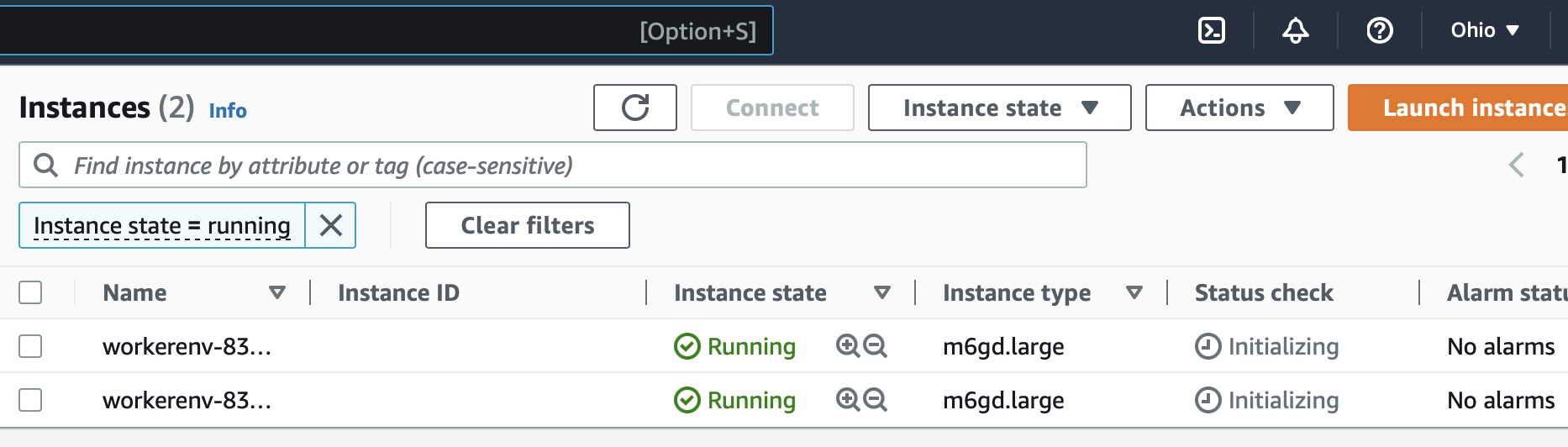
- Create cluster under the create cluster tab. Settings as below
# high concurrency is for a shared cluster Cluster Mode = Standard # Turn off Autopilot Terminate after = 15 mins # 10 cents an hour. Cheapest I can find. Worker, Driver Type = m6gd.large Num workers = 1 - This spun up two instances on aws.
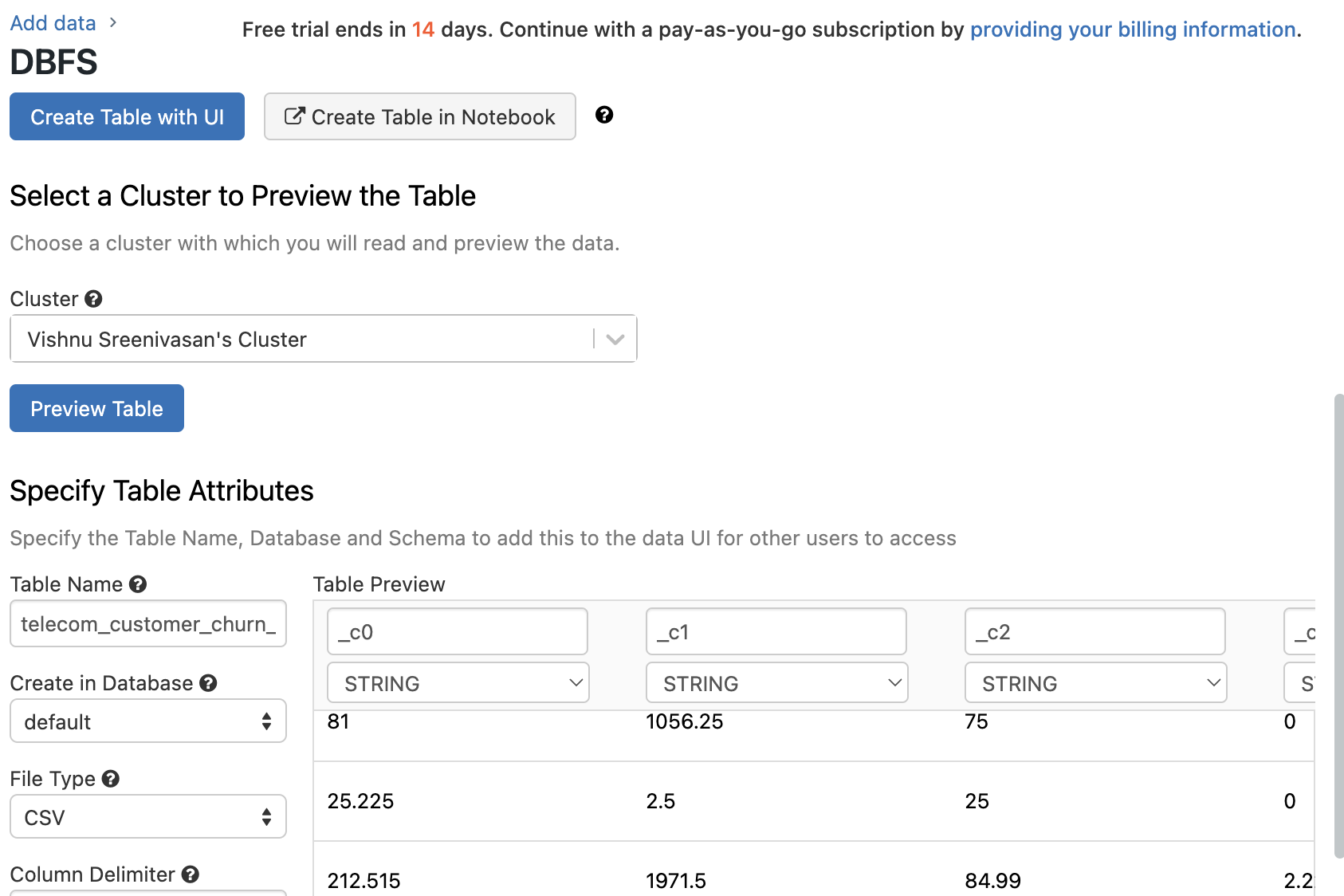
Add data
Let’s first create a table, this can be done in the workspace console
Data -> Table -> Create table. For data, we are using this telecommunication data from
kaggle. We are going
to directly upload the data from this csv file into DataBricks DBFS fmt table creator.
Create a notebook in databricks
We create a spark notebook with databricks.
Teardown
In order to teardown the resources, we need to
- pop into the VPC section of aws
- delete the NAT device
- delete the databricks VPC
- delete the associated elastic IP address