Machine Learning Assignments and Projects Posted on January, 20th, 2014
Machine Learning was one of the most satisfying courses I have taken
at Penn. I felt so much more empowered at the end of this course and
I knew I was ready to tackle real world problems. ML was a
fundamental introduction to the mathematics, algorithms and practice
of machine learning. Topics covered include: Supervised learning:
least squares regression, logistic regression, perceptron, naive
Bayes, support vector machines. Model and feature selection,
ensemble methods, boosting. Learning theory: Bias/variance tradeoff.
Online learning. Unsupervised learning: Clustering. K-means. EM.
Mixture of Gaussians. PCA. Graphical models: HMMs, Bayesian and
Markov networks. Inference. Variable elimination. Miscellaneous:
Introduction to Active Learning and Big Data. All the programming
was done in Matlab.
For the sake of prevention of copying of homework of solutions, I am
not including any graphs or results from the homework.
Assignments
- Implemented decision trees, Adaboost, Perceptrons, SVM (using libsvm) for classification of "MNIST dataset" and studied their learning curves and accuracy.
- Implemented Naive Bayes and Logistic Regression for classification "breast cancer Wisconsin dataset".
- Also studied the effect of PCA of noisy data used for classification and the drop in reconstruction error for addition of each component of a PCAed data.
Final Project
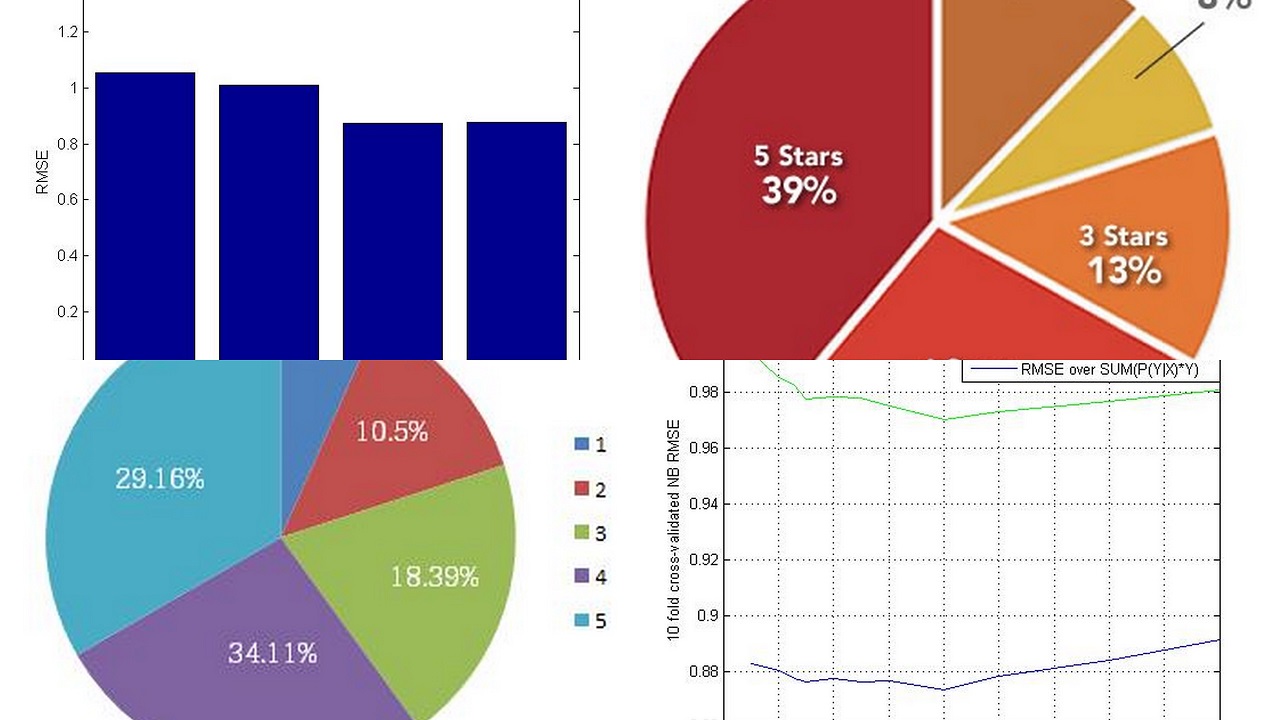
The task was to predict the rating of a restaurant from a short descriptive review written by a user. The dataset chosen for this particular task were the reviews obtained from the yelp website. The problem was formulated as a regression task rather than a classification task and (Root mean square error) RMSE was measured. Correlation test was used for feature selection and feature transformation algorithms, including TFIDF, correlation based feature weighting with sentiment analysis, PCA and classification algorithms, including Logistic regression, Naive Bayes, Perceptrons, SVM, Random forests etc. were employed and the optimal combination was chosen. The final algorithm employed was a combination of Logistic Regression with Naïve Bayes and was able to achieve significantly low RMSE in the out of sample test data and was significantly faster than most of the other algorithms employed.
Our team came 14th out of the 47 teams in class and we also had the second fastest algorithm in the top 15.